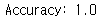from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.datasets import load_iris
# 아이리스 데이터셋 불러오기 iris = load_iris() X = iris.data y = iris.target