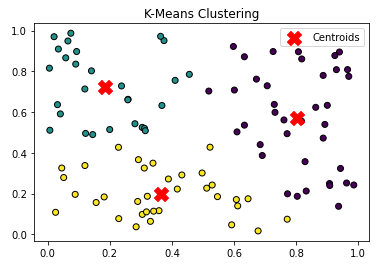
K-평균 군집화
- 비지도 머신러닝 알고리즘
- 데이터 세트를 K개의 클러스터로 분할하는 것이 목표
- 각 군집은 서로 유사한 데이터 그룹
중심
- 클러스터의 중심을 나타내는 특징, 공간의 지점인 K개의 중심을 식별
- 처음에는 중심이 데이터에서 무작위로 선택
배정 단계
- 각 데이터는 중심에서 가까운 군집에 할당(유클리드 거리 사용)
업데이트
- 데이터를 할당 후 데이터의 평균으로 다시 계산
반복
- 배정과 업데이트를 수렴될 때까지 반복
K선택
- 알고리즘을 실행하기 전에 지정해야하는 매개변수 K
- 최적 값을 찾기 위해 실루엣 분석 등 사용
1 | from sklearn.cluster import KMeans |