ARIMA(자기회귀 통합 이동 평균)
자기회귀(AR) 구성요소(p)
- 자기회귀 구성 요소는 관찰과 일부 지연된 관찰(이전 시간 단계)간의 관계 캡처
- “p”라는 용어는 자기회귀 구성요소의 순서를 나타내며, 고려되는 지연된 관측치 수
통합(I) 구성요소(d)
- 통합 구성 요소에는 시계열 데이터를 차별화하여 고정시키는 작업이 포함,
정상성은 평균, 분산 등 시계열의 통계적 속성이 시간이 지나도 변하지 않는 것을 의미 - “d”라는 용어는 정상성을 달성하는 데 필요한 차분의 차수
이동평균(MA) 구성요소(q)
- 이동 평균 구성 요소는 시차 관측에 적용된 이동 평균 모델의 관측과 잔차 오차 간의 관계를 나타냄
- “q”라는 용어는 이동 평균 성분의 차수를 나타내며, 시차 잔차가 얼마나 고려되는지 나타냄
- p : 자기회귀 구성요소의 순서
- d : 차분의 순서
- q : 이동평균 구성요소의 순서
1 | pip install statsmodels |
1 | import numpy as np |
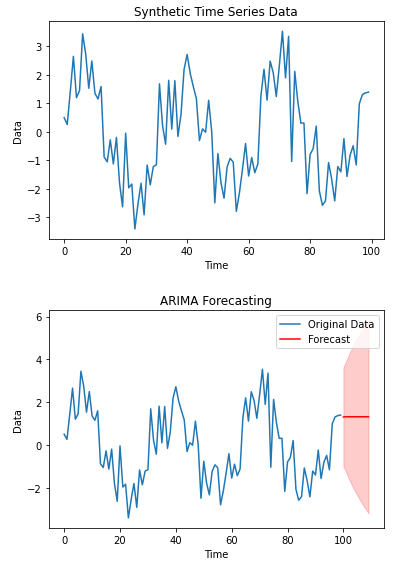
ARIMA는 계절성, 추세, 노이즈 등 요인에 따라 성능에 영향을 받을 수 있음