references
YOLO, YOLOv2 and YOLOv3
- Object Detection : Deep Learning의 Computer vision 분야에서 가장 주목받는 주제 중 하나이다.
- EX) RCNN, RetinaNet and YOLO(you only look once)
1. Object Detection
- 이미지 혹은 비디오 스트림이 주어지면, object detection 모델은 객체들의 모임 중에서 어떤 것이 존재할 수 있는지 식별하며 이미지 안에서 그들의 위치들에 대해 정보를 제공할 수 있다.
Object Detection은 single object를 분류하고 이미지에서 그 object의 위치를 결정하는 classification with localization과는 다르다.
1-1. IOU(Intersect Over Union)
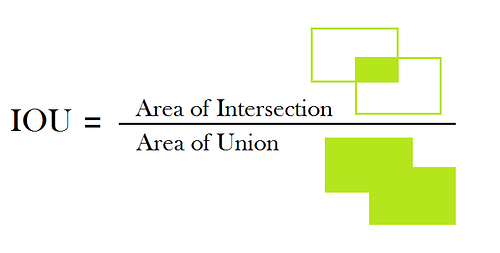
- IOU는 교차 영역을 두 box의 전체 영역으로 나누어 계산할 수 있다.
- IOU는 0과 1사이
- 아래의 그림에서 왼쪽 사진은 교차영역이 오른쪽 사진보다 작다.
오른쪽 사진은 거의 완벽하게 교차하였기 때문에 IOU는 1에 가까워지는 것이다.
1-2. Precision(정밀도)
- Precision(정밀도)는 진양성을 양성예측으로 나눈 것으로 정의할 수 있다.
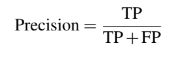
- 예를 들어 20 개의 이미지가 있고 20개의 이미지에서 120대의 자동차가 있다는 것을 알고 있다고 가정
- 이미지를 모델에 입력하고 -> 100대의 자동차를 감지했다고 가정
- 20개가 잘못된 경우 정밀도는 80/100 = 0.8 이다.
만약 예측된 box와 ground truth box 사이의 IOU가 임계값(0.5,0.75,..)보다 작으면 부정확한 예측이 될 수 있다.
1-3. Recall(재현율)
- 위의 정밀도를 구하는 예제를 봤을 때, 자동차의 total 갯수를 고려하지 않았다. 그래서 120대 대신에 1000대의 자동차들을 사용한다고 가정하고, 그 모델 output이 80대가 있는 100개의 box가 맞다면 Precision은 다시 0.8이 된다.
- 그렇다면 이 문제를 해결하기 위해 우리는 재현율이라는 개념을 사용해야 한다.
- 아래의 식과 같으며 Recall은 진양성에서 실제 양성으로 나눈 것으로 정의할 수 있다.

- recall = 80/120 = 0.667
- 재현율이 데이터에서 object들을 detect하는데 좋다는 것을 확인하였다.
1-4. Average Precision and Mean Average Precision(mAP)
- Average Precision을 간략하게 정의하면 Precision-Recall Curve의 아래에 있는 영역을 의미한다.
- AP는 Precision과 Recall을 결합한 것이다.
- AP는 0과 1사이에 존재하며, 높을 수록 더 좋은 것이다.
- AP=1을 얻기위해서는 Precision과 Recall이 1로 같아야한다.
- mAP는 모든 class에 대해 계산된 AP의 평균을 의미한다.
2. YOLO
- YOLO란??
- 많은 object detection은 이미지의 모든 object를 detect하기 위해 이미지를 한 번 이상 통과해야하거나 object를 detect하기 위해 2-step을 거쳐야 한다.
- YOLO는 이런 과정을 거칠 필요가 없다
- 모든 object를 detect하기 위해 이미지를 한 번만 보면 된다.
- 즉, YOLO(You Only Look Once) 해석 그대로 받아드리면 된다.
- 실제로 YOLO가 매우 빠른 모델인 이유이다.
3.YOLO (YOLOv1)
- YOLO는 이미지를 S*S 그리드로 나눈다.
- EX) 아래의 이미지는 5*5로 나누었으며, 만약에 Grid Cell안에 object가 위치해 있을 때, 그 grid cell은 object를 detect한다.

- YOLO는 7*7 = 49 grid cell 각각에 대해 동시에 Classification과 Localization 문제를 run한다.
- Classification과 Localization network는 오직 하나의 object만 detect할 수 있기 때문에 그 말은 즉, 어떤 grid cell은 오직 하나의 object만 detect할 수 있다.
- 따라서 아래와 같은 문제들을 직면하게 된다.
- 7*7 grid 를 사용하기 때문에 어느 grid는 하나의 object만 detect할 수 있고, 그 최대 object의 갯수는 49개만 가능하다는 것이다.
- 만약 grid cell이 하나의 object보다 더 많은 object를 포함하게 된다면?
그 모델은 모든 object에 대하여 detect를 할 수 없을 것이다.
따라서 Close Object Detection는 YOLO가 겪고 있는 문제이다.
- Object가 하나의 grid의 면적을 넘어 차지하고 있다면(위의 택시처럼), 그 모델은 한 번이 아니라 다른 grid에서도 taxi라 detect 할 수 있다.
따라서 이 문제는 “Non-Max Suppresion”를 사용하여 해결한다.
- 49개 cell 모두 동시에 detect되어지며, 그것이 바로 YOLO가 매우 빠른 모델인 이유이다.
- 7*7 gric cell의 각각은 B Bounding boxe들을 예측하고(YOLO chose B =2), 각각의 박스, 모델의 output은 confidence score이다.
- confidence score 상자가 모델을 포함하는 모델을 얼마나 확신하는지를 반영한다.
- confidence score을 사용하여 모델이 배경을 감지하지 못하도록 막을 수 있으며 cell에 object가 없으면 confidence score은 0이 되어야한다. 만약 그렇지 않으면, confidence scroe가 예측된 box와 ground truth 사이의 union을 통한 IOU가 같기를 원한다.
- 왜 C= IOU 인가요? ground truth box는 손으로 그려졌기 때문에 ground truth box 안에 object가 있다는 것을 100% 확신한다. 따라서 truth box안에 있는 높은 IOU를 가진 box는 또한 같은 object를 둘러싸고, IOU가 높을 수록 predict box 내부에 object가 있다는 가능성이 높아진다.

- 7*7 =49 개의 cell들이 있고 각 cell들에 대해 2개의 상자(total 98개)를 예측함
- box의 대부분은 매우 낮은 신뢰도(confidence)를 가지므로 제거할 수 있다.
- 추가로 confidence score(C)에 모델은 4개의 숫자를 출력한다. ((x,y),w,h)는 predeict bounding box의 위치를 나타낸다.
- (x,y)는 grid cell의 bound를 기준으로 box의 중심을 나타낸다.
- width와 height은 전체 이미지를 기준으로 예측된다.\
- YOLO는 20개의 다른 object들의 class들을 detect하도록 훈련되어 진다.
- 어떤 grid cell에서든지, 그 모델은 20개의 conditional class probabilities를 출력한다.
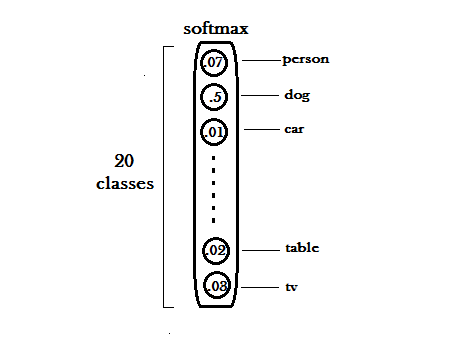
- 반면에 각각의 grid cell은 우리에게 2개의 bounding box들 사이의 choice를 주며, 우리는 오직 하나의 class probalility vector를 가질 수 있다.
- 우리는 가장 낮은 신뢰도를 가진 box를 제거 할 수 있다.
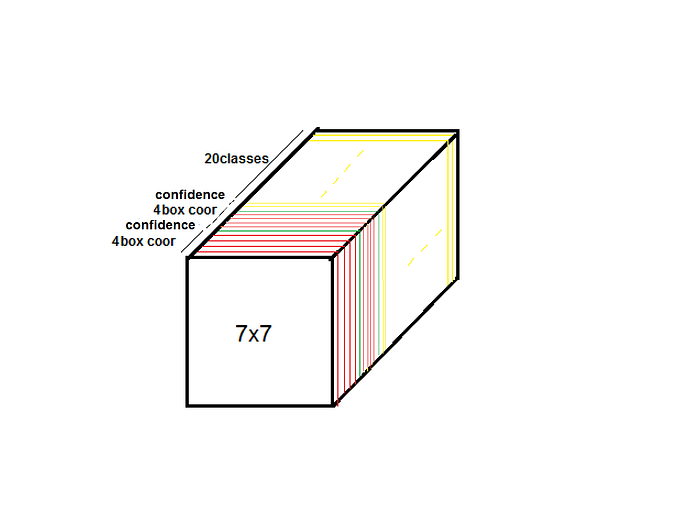
3-1. Output Shape

- 예측은 SxSx(Bx5 + classes) tensor로 암호화되어진다.
- EX) S=7, B=2, Classes = 20 총 7x7x30 tensor 이다.
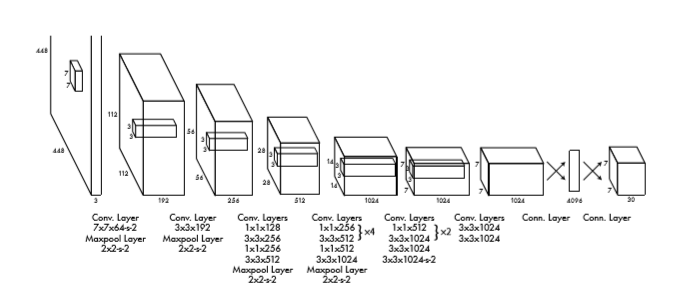
3-2. Network Design
- YOLO는 하나의 Convolutional network를 사용하여 여러개의 bounding box들과 그 box들에 대한 class probabilities를 예측한다.
- 이 네트워크는 이미지 분류 모델인 GoogleNet에 의해 영향을 받았지만, GoogleNet에 사용되어진 inception 모듈 대신에 YOLO는 단순하게 3x3 convolutional layer(컨볼루션 레이어)와 1x1 reduction layer(축소 레이어)을 사용한다.
- 24개의 convolution layer와 2개의 완전히 연결된 layer들이 있다.
- 위에서 언급한 대로, 네트워크의 최종 output은 7x7x30 tensor로 예측한다.
3-3. Loss Function
- YOLO는 손실함수로서 SSE(Sum-squared Error)를 사용한다.
- optimize하게에 쉽기 때문이다.
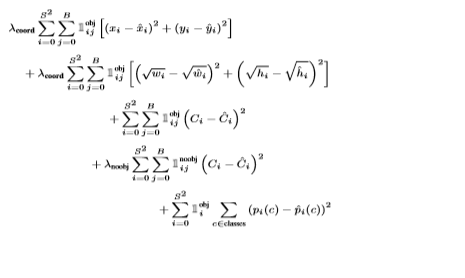
- 위의 식에서 첫번째, 두번째 식은 localization loss이고,
3번째, 4번째 식은 confidence loss이며
마지막 식은 classification loss를 나타낸다.
3-4. Training
- 먼저, ImageNet 1000-class 대회 데이터 셋에서 분류에 대한 네트워크의 convolutional layer들을 사전훈련 시킨다.
- 사전훈련을 위해 첫 20개 convolutional layer들을 사용했고, 그 다음에 평균 pooling layer와 224x224의 input 사이즈를 가진 1x1000 인 fully connected layer를 사용했다.
- 이 network는 top-5의 정확도인 88%에 도달했다.
- 그 다음 1x1000 fully connected layer와 추가적으로 4개의 convolutional layer 그리고 2개의 fully connected layer를 랜덤하게 초기화한 가중치를 더했다.
- 그리고 224x224 에서 448x448 로부터 네트워크의 input resolution을 증가했다.
- 그 후 detect를 위해 모델을 훈련시켰다.
3-5. Non-Maximal Suppression
- YOLO는 7x7 grid를 사용하므로 만약 object가 하나의 grid 보다 더 차지한다면 이 object는 다른 grid에서도 detect될 수 있다.
- 한번에 하나만 detect되어야 하기 때문에, 예를 들어 아래의 이미지에서 택시의 yellow box가 3개나 dectect 되었다.
- 실제로 1개만 detect되어야 하는데 세 번 이상 detect 된 격이다.

그렇다면 이 yellow box 들 중 하나만 선택하는 방법은?\
- 각 class에 대해 수행하자\
- C < C 임계 값(ex.C < 0.5)를 사용하여 모든 box를 제거한다.\
- 가장 높은 신뢰도 C에서 시작하여 예측을 정렬한다.\
- C가 가장 높은 상자를 선택하고 예측을 출력한다.\
- 이전 단계의 box와 함께 IOU>IOU-treshold 가 있는 box들을 모두 제거한다.\
- 모든 나머지 예측을 확인할 때 까지 4단계부터 다시 시작한다.
Non-Maximal Suppresion 에서 2-3%를 추가한다.
3-6. Fast YOLO and YOLO VGG-16
Fast YOLO는 YOLO의 빠른 버전이다.
fast YOLO는 24개 대신에 9개의 convolutional layer을 사용한다.
YOLO보다 더 빠르지만 더 낮은 mAP를 가진다.
YOLO VGG-16은 오리지널 YOLO 네트워크 대신에 그것의 backbone을 VGG-16을 사용한다.
좀 더 정확하지만 실시간보다 좀 더 느리다.
3-7. Limitations of YOLO
- 각각의 grid cell은 오직 2개의 box들을 사용하여 예측하고 하나의 class만 예측할 수 있기 때문에 YOLO가 예측할 수있는 nearby object의 수를 제한한다. 특히 새의 무리와 같이 그룹을 나타내는 작은 object의 경우에 그러하다.
- YOLO는 7x7 = 49개의 물체만 감지할 수 있다.
- 비교적 높은 localization 오류
4. YOLOv2
- YOLO ver1은 상당히 많은 localization error들을 만든다.
- 게다가, YOLO는 비교적 낮은 재현율을 보인다.
- 그러므로 YOLO의 두번째 버전은 classification accuracy를 유지하면서 localization(위치)과 재현율을 향상시키는 것이 목표이다.
- 아래의 방법이 YOLOv2의 성능을 좋게 만드는 idea이다.
- BatchNormalization: YOLO의 모든 컨볼루션 레이어들에 batch normalizaition을 더함으로써 mAP가 2% 향상되었다.
- High Resolution Classifier: YOLO ver1은 아래와 같이 훈련되어졌다.
- 224x224에 classifier network를 훈련시켰다.
- detection을 위해 resolution(해상도)를 448로 증가시켰다.
- 이 뜻은 detection으로 전환할 때 네트워크가 동시에 학습 object detection으로 전환하고, 새로운 input resolution으로 조정한다.
- YOLOv2 를 위해 처음에 224x224 인 이미지에 모델을 훈련시키는 동안, full 448x448 이미지에 classification network를 fine tune한다 (dectection을 하기 위한 훈련 전에 ImageNet의 10 epochs 에 대해).
- 더 높은 resolution input에 더 나은 동작을 하도록 그것의 filter들을 조절하기 위한 network 시간을 제공한다.
- high-resolution classification network는 거의 4% 증가된 mAP를 제공한다.
- Convolutional With Anchor Boxes(한 cell당 여러개의 object 예측)

- YOLOv1은 object의 중심을 포함하는 grid cell에 object를 할당하려한다.
- 이 아이디어를 사용하여 위의 이미지에 빨간 셀에는 man과 necktie를 감지해야한다.
- 그러나 grid cell은 오직 하나의 cell에 하나의 object만 detect할 수 있다.
- 이것을 해결하기 위해 저자는 k bounding box를 이용해 하나의 object보다 더 많은 object를 detect하도록 했다.
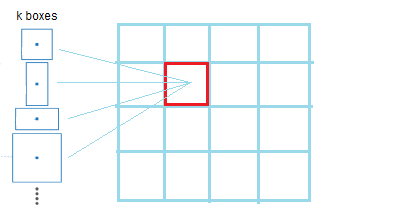
> k bounding box를 예측하기 위해 YOLOv2는 Anchor boxes의 아이디어를 사용했다.
4-1. Anchor Box
- 그렇다면 Anchor Box는 무엇일까?
- YOLO는 컨볼루션 feature extractor의 위에서 완전히 연결된 layer들을 사용해서 바로 bounding box들의 좌표를 예측한다.
- 좌표를 바로 예측하는 대신에 Fater R-CNN인 다른 object detection 모델은 내가 직접 고른 anchor box들을 사용해서 bounding box를 예측한다.
- 우리는 이미지를 기준으로 박스의 예측하는 것 대신에 bounding box를 기준으로 bounding box를 예측할 수 있다.
- 이 아이디어를 사용해서 network가 더 쉽게 학습할 수 있다.
- 오직 컨볼루션 레이어들(완전히 연결된 layer들 제외)들인 Faster R-CNN은 offset과 anchor box들의 신뢰도를 예측한다.
- 아래의 이미지는 Grid cell(빨간 박스)과 5 anchor box들(노란 박스)과 함께 다른 모양을 가진다.
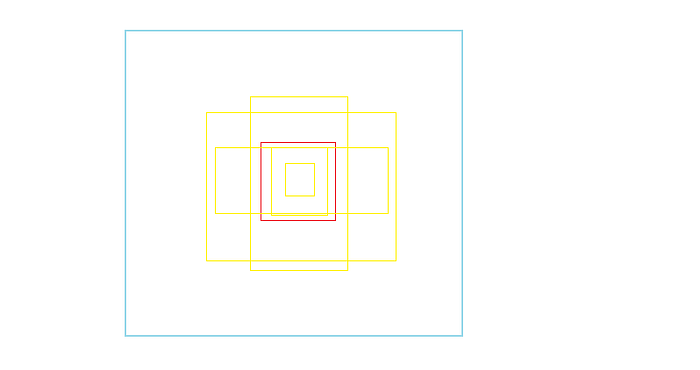
- YOLOv2는 손으로 직접 k anchor box를 고르는 것 대신에 anchor box들의 아이디어를 사용하려 한다.
- detection을 훈련하려는 네트워트를 더 쉽게 만들기 위해 가장 best인 anchor box를 찾으려 한다.
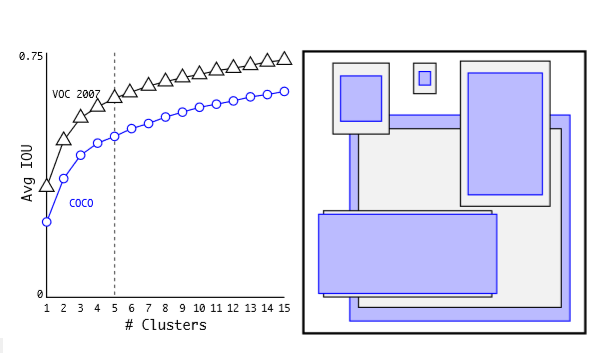
- 아래의 이미지는 5개의 red box들은 평균 dimension들과 VOC 2007 데이터셋의 object들의 위치를 나타낸다.
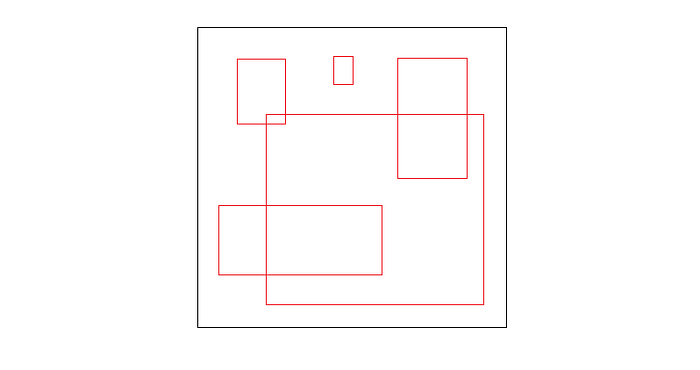
- 왜 5개의 박스들을 가지는지 궁금할 것이다!
- k-means clustering을 수행하는데 k개의 다양한 값에 대해 훈련 데이터셋의 bounding box에서 실행한다.
- 가장 가까운 중심으로 평균 IOU를 plot하지만, 유클리디안 거리 방식을 사용하는 대신에 bounding box와 중심 사이의 IOU를 사용한다.
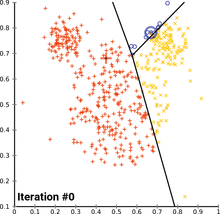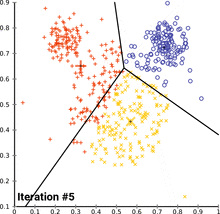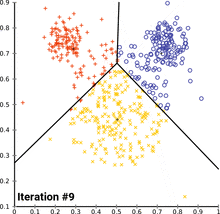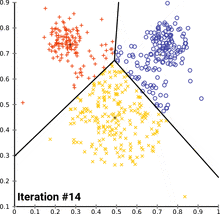
- 모델의 복잡성과 높은 재현율 사이의 가장 좋은 트레이드오프로써 k=5로 선택된 것이다!
- YOLOv2는 grid cell의 위치를 기준으로 location coordinate를 예측한다.
- 이 예측은 ground truth를 0과 1 사이로 제한한다.
- 네트워크는 각 cell 당 5개의 bounding box들을 예측한다.
- 즉, 각 bounding box들에 대해 5개의 좌표를 예측한다는 것이다.
- tx,ty,tw,th 그리고 to
- 만약 그 cell이 왼쪽 위쪽 코너로 부터 (cx,cy)만큼 오프셋되고, 그리고 bounding box prior(anchor box)에 width, height pw,ph를 가진다면 아래의 예측과 일치한다.
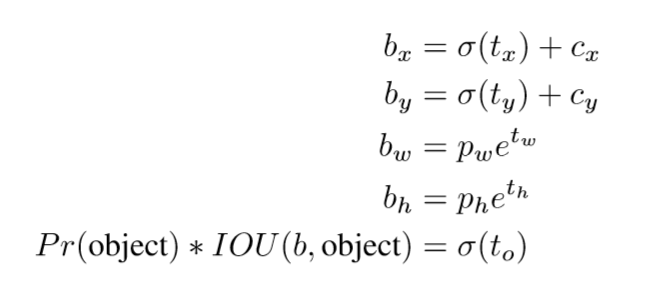
- 예를 들어, 만약 2개의 anchor box를 gird cell(2,2)에 사용하는데 아래의 이미지에서 2개의 box들(blue, yellow)를 output할 것이다.
- cell에 해당하는 2 anchor box들을 검정 점 박스가 대표한다.
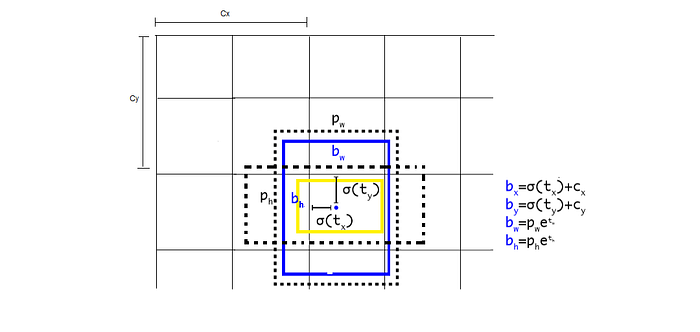
- 위의 그림에서 파란 박스만 고려해보자, YOLO ver1에서는 오직 하나의 grid cell로서 예측된 파란 박스를 할당하는 대신에!
- YOLOv2는 그 grid cell 뿐만 아니라 anchor box들 중 하나까지 할당한다.
- 그리고 그것은 ground truth box와 함께 가장 높은 IOU를 가진 것이 될 것이다.
- YOLOv2는 grid와 anchor box에 파란 박스를 할당하기 위해 위의 방정식을 사용한다.
4-2. Network Architecture
1) Darknet-19
- 복잡성과 정확도 문제를 해결하기 위해 저자는 YOLOv2의 backbone으로 사용할 Darknet-19라는 새로운 classification model을 제한했다.
- Darknet-19는 19개의 컨볼루션 layer들과 5개의 max-pooling 레이어들을 가진다.
- ImageNet의 top-5의 정확도인 91.2%를 달성했고 그것은 VGG(90%)보다 나으며 YOLO network(88%)보다 높다.
2) Output Shape
- YOLOv2의 output shape은 13x13x(k.(1+4+20)) 이며 k는 anchor box들의 수이다.
- 20은 class들의 수 이다.
- k=5에 대한 output shape은 13x13x125가 될 것이다.
3) Training
- 그 모델은 classification에 대한 훈련이 처음되고 그 다음 detection에 대한 룬련이 되어진다.
(1) Classification: 160 epoch과 224x224인 input shape의 ImageNet 1000 클래스 분류 데이터셋에서 Darknet-19 네트워크를 훈련했고, 그 후 10 epoch동안 448x448인 큰 input 크기로 네트워크를 미세조정하게 된다. 이것은 76.5%의 top-1정확도와 93.3%의 top-5 정확도를 제공한다.
(2) Detection: classification 에 대한 훈련 후에 Darknet-19로 부터 마지막 컨볼루션 레이어를 제거한다. 그리고 대신에 3x3 컨볼루션 레이어와 output의 수인 1x1 컨볼루션 레이어를 더한다.(detection에 필요한 13x13x125)- 또한, passthrough 레이어는 이전의 레이어로부터 모델에 더 좋은 grain feature들을 사용하기 위하여 추가된다.
- 그런 다음 detection 데이터셋(VOC, COCO datasets)에 160번의 epoch을 한 network를 훈련시킨다.
4) Multi-scale Training
- YOLOv2가 서로 다른 크기의 이미지에서 수행되도록 서로 다른 input size에 대해 모델을 훈련시킨다.
- input size를 수정하는 대신 몇 번의 반복마다 네트워크를 변경한다.
- 매 10 batches 후에 네트워크는 랜덤하게 새로운 차원 사이즈를 고르는데 dimensions set(320,352,384,…,608)로 부터 구한다.
- 해당 dimension에 맞게 네트워크 size를 조정하고 훈련을 계속한다.
- 동일한 네트워크가 다른 resolution에서 물체를 예측할 수있음을 의미한다.
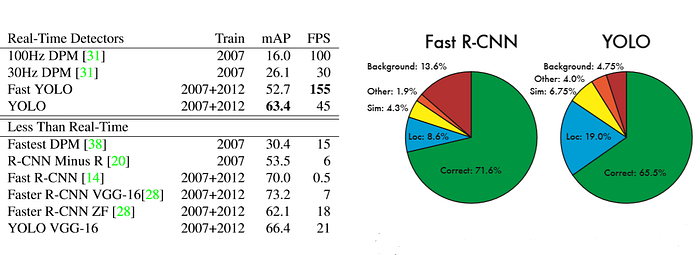
5) Comparision to Other Dectection Systems
- YOLOv2는 최신식이며 다른 detection 시스템 보다 더 빠르다.
- 게다가, 다양한 이미지 사이즈에 동작될 수 있다. 속도와 정확도 사이의 부드러운 트레이드 오프를 제공한다.
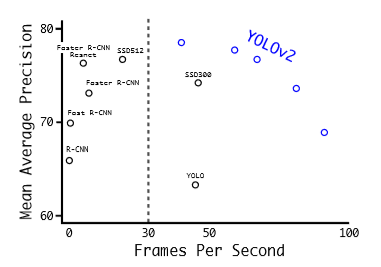

위의 결과: PASCAL VOC2012 테스트 detection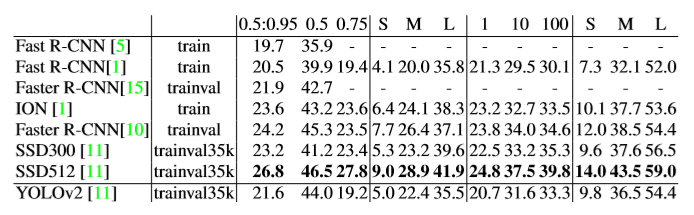
위의 결과: COCO test-dev2015
4-3. YOLO9000
- 20개 class 이상의 detect가 필요할 경우, YOLO9000을 사용하면 된다.
- 실시간 프레임워크이며 9000개 object 카테고리보다 더 많이 감지하기 위해 사용한다. 또한 detection과 classification을 함께 최적화한다.
- YOLOv2는 classfication에 대한 훈련 후에 detection 훈련을 한다.
- 이러한 이유는 하나의 object를 포함하는 classfication에 대한 dataset은 dectection에 대한 데이터셋과 다르다.
- YOLOv2에서 저자는 classification에 대한 훈련과 dectection data를 함께 훈련하는 매커니즘을 제안한다.
- 훈련하는 동안, dectection과 classification 데이터셋 둘로 부터 이미지를 섞는다.
- 네트워크가 dectection을 위한 label된 이미지를 발견하면, full YOLOv2의 손실함수를 기반으로 역전파할 수 있다.
- detection과 classification data를 섞는 아이디어는 새로운 도전을 직면한다!
- detection 데이터셋들은 classification 데이터셋들과 비교해서 작다.
- detection 데이터셋들은 오직 공통인 object들과 일반적인 label만 가진다. 마치 dog 혹은 boat 처럼!
- 반면에 classification 데이터셋들은 더 넓고 깊은 범위의 label들을 가진다.
- 예를 들어, ImageNet 데이터셋은 “german shepherd”그리고 “Bedlington terrier”과 같은 개들의 백여가지 보다 더 많은 걸 가진다.
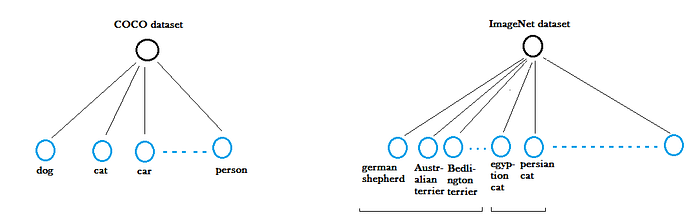
- 이러한 두 데이터셋들을 병합하기 위해 저자들은 *wordtree라고 부르는 것과 visual comcept들의 계층적 모델들을 만들었다.
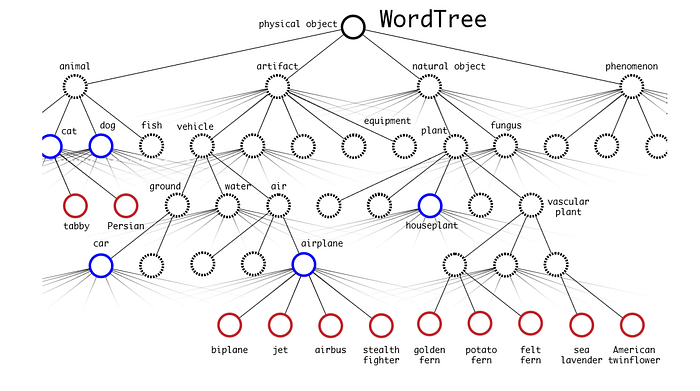
- 모든 클래스들은 ROOT 아래에 위치해 있다.
- WordTree에서 DarkNet-19 모델을 훈련시켰다.
- WordTree로 부터 ImageNet 데이터셋의 1000개 class들을 추출했고, intermediate node들을 그것에 추가했다. 그리고 그것은 1000개에서 1369로 label space를 확장했다. 그리고 그것을 WordTree1k라고 불렀다.
- 지금은 Darknet-19의 output layer의 사이즈는 1000개 대신에 1369개가 되었다.
- 1369개의 예측들은, 하나의 softmax를 계산하지 않지만 동일한 개념인 분리된 softmax의 전반적인 synset들을 계산한다.
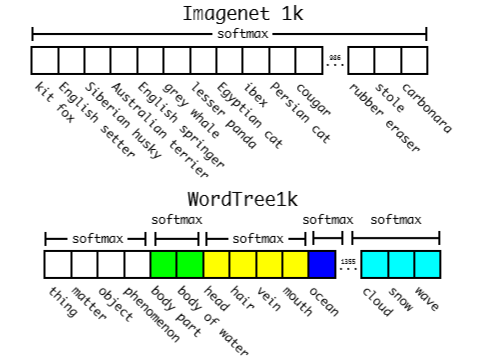
- Darknet-19에 369개의 추가적인 개념들을 더함에도 불구하고 71.9%의 top-1 정확도와 90.4%의 top-5의 정확도를 달성했다.
- detector은 bounding box와 tree의 probabilities를 예측하였지만, 둘 이상의 softmax를 사용하기 때문에 우리는 예측된 class들을 찾기위해 tree를 탐색해야 한다.
- tree의 위에서 아래까지 탐색하는데 threshold-probability보다 작아지는 확률에 도달하기 까지 매 split마다 가장 높은 신뢰도를 가져야 한다. 그리고 object class를 예측한다.
- 예를 들어, 만약 input image에 dog를 포함한다면, 그 트리의 확률은 아래와 같이 나타난다.

- 모든 이미지가 object를 가진다고 추정하는 대신에, YOLOv2의 objectness 예측기를 사용하여 root인 Pr(물리적 객체)의 값을 제공한다.
- 그 모델은 각 branch level에 대한 softmax를 출력한다.
- 우리가 위에서부터 아래로 움직이면서 가장 높은 확률(만약 threshold value보다 높다면)을 가진 노드를 고른다. 예측은 우리가 멈춘 노드가 될 것이다.
- 위의 트리에서, 모델은 physical object=> dog => hunting dog 순으로 겪는다.
- hunting dog에서 멈출 것이고 sighthound로 내려가지 않을 것이다. 왜냐하면 그것의 신뢰도는 threshold 값보다 더 낮은 신뢰도를 가지기 때문이다. 그래서 그 모델은 sighthound가 아닌 hunting dog를 예측하는 것이다.
5. YOLOv3
- 전 버전 보다 좀 더 크지만 더 정확하다.
5-1. Bounding Box Prediction
YOLO9000과 같이, 네트워크는 각 bounding box마다 4개의 좌표를 예측한다.
만약 그 cell이 (cx,cy)의 위쪽왼쪽 코너로 부터 떨어져있다면 bounding box prior은 width, heigh, Pw,Ph를 가지고 그런 다음 예측은 아래와 같이 일치한다.
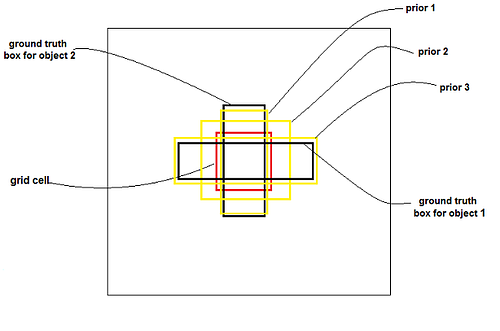
YOLOv3는 또한 logistic regression을 사용하여 각 bounding box에 대한 신뢰도를 예측한다.
이것은 1이될 것이다. 만약 bounding box prior이 다른 bounding box prior보다 더 많은 것에 의해 ground truth object가 오버랩한다면!
예를 들어(prior 1), 이전의 다른 bounding box보다 더 많이 첫번째 ground truth object보다 겹치고, prior2가 두번째 ground truth object와 겹친다.
시스템은 각 ground truth object에 대해 하나의 bounding box만 우선 할당한다.
bounding box prior이 ground truth object에 할당되지 않은 경우 좌표 또는 클래스 예측에 대한 손실은 발생되지 않으며 오직 objectness만 발생한다.
만약 box가 가장 높은 IOU를 가지진 않지만 thresold 값 이상으로 ground truth object와 더 많이 겹치면 우리는 예측을 무시해도된다. (이때, thresold값 0.5)
5-2. Multi labels predection
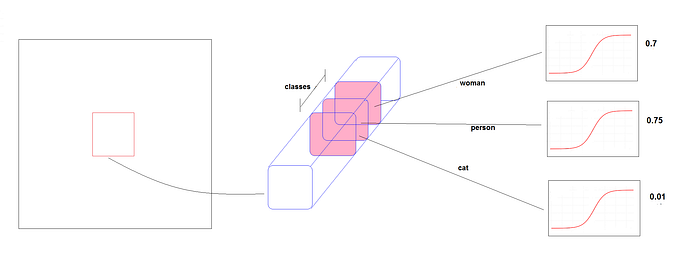
- Open Image dataset과 같이 몇몇의 데이터셋들은 여러개의 label을 가질 수도 있다. 예를 들어, 하나의 object는 woman, person으로 label될 수 있다.
- 이 데이터셋에서, 많은 overlapping label이 존재한다.
- 클래스 예측에 대한 softmax를 사용하는 것은 각 box가 정확하게 하나의 class만 가진다는 가정을 두는 것이고, 그리고 그것은 종종 그렇지 않다.
- 이런 이유로 YOLOv3는 softmax를 사용하지 않는다.
- 대신 모든 class에 대해 독립적인 logistic classifier을 사용한다.
- 훈련 중에 class 예측을 위해 binary cross-entropy loss를 사용한다.
- 독립적인 logistic classifier를 사용하면, 한 object가 동시에 person으로서 woman으로서 detect될수 있다.
5-3. Small Objects Detection
- YOLO는 작은 object에 문제가 있었다.
- 그러나 YOLOv3는 작은 object에 더 나은 성능을 보인다. 왜냐하면 short cut connection을 사용하기 때문이다!
- short cut connetion 방법을 사용하는 것은 earlier feature map으로 부터 finer-grained information을 얻을 수 있다.
- 그러나 이전의 버전과 비교해서, YOLOv3는 medium과 large 사이즈 object에 대해 좀 더 안좋은 성능을 가지고 있다.
5-4. Feature Extractor Network(Darknet-53)
- YOLOv3는 feature extraction을 수행하는데 새로운 네트워크를 사용한다.
- YOLOv2(Darknet-19)에서 사용된 네트워크와 residual 네트워크 사이의 하이브리드 접근법이다.
- 그래서 몇몇의 short cut connection을 가진다.
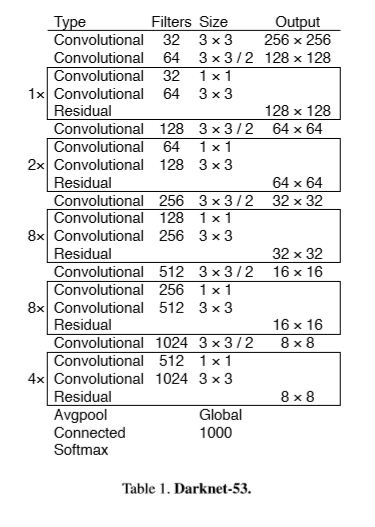
- 53개 컨벌루션 레이어들을 가진다. 그것을 Darknet-53라 부른다.
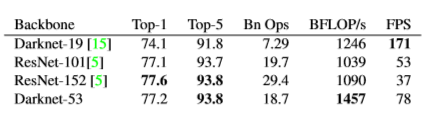
- Darknet-53은 최신식의 classifier와 동등한 성능을 제공하지만 floating 작업이 적고 속도도 더 빠르다.
classification 훈련후에 완전이 연결된 레이어는 Darknet-53으로 부터 제거되었다.
5-5. Predictions Across Scales
- YOLO와 YOLOv2와 다르게, 마지막 레이어에서 output을 예측한다.
- YOLOv3는 아래의 이미지에서 3개의 다른 규모들인 box들을 예측한다.
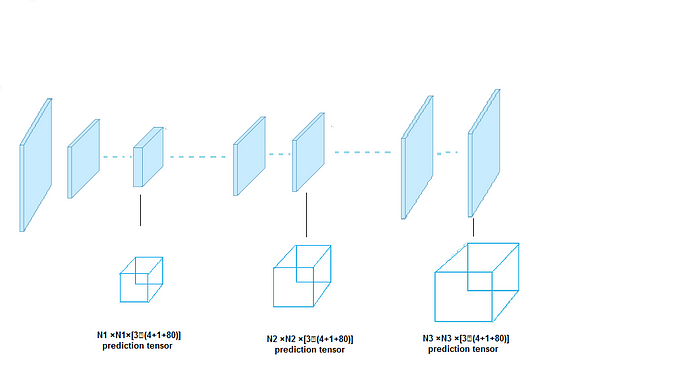
이것은 네트워크에 대한 간단한 diagram이다.
- 각각의 scale YOLOv3는 3개의 anchor box들을 사용하고 어떤 grid cell에 대해 3개의 box들을 예측한다.
- 각 object는 여전히 하나의 detection tensor에서 하나의 grid에 할당되어진다.
5-6. Performance
AP50에서 정확도 vs 속도를 볼때, YOLOv3는 다른 detection 시스템을 넘어 상당한 benefit을 가진다.
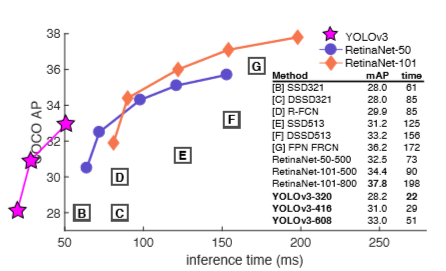
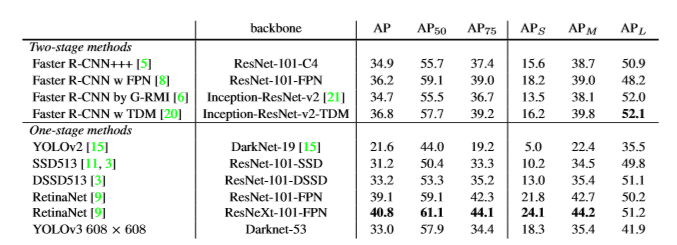
그러나, YOLOv3 성능은 IOU threshold 증가함에 따라 떨어진다.
YOLOv3는 object와 box를 완벽하게 분리하지는 못하지만, 그래도 다른 방법들보다는 빠르다.